
Frames是Runway推出的最新AI圖像生成模型,在風格控制和視覺保真度方面取得巨大進步。Frames能維持風格一致性,支持廣泛的創意探索,為項目建立特定外觀,并生成符合用戶美學的變體。基于Frames,用戶能精確設計想...
網站首頁 > AI工具 第10頁
-

-

SlideChat是上海AI實驗室、廈門大學、華東師范大學等機構推出的,首個能理解千兆像素級別全切片圖像的視覺語言助手。SlideChat能生成詳盡的全切片圖像描述,并針對多樣化的病理場景提供具有上下文關聯的復雜指令響應。基...
-
書生InternThinker是上海人工智能實驗室推出的強推理模型,具備自主生成高智力密度數據和元動作思考能力。基于長思維能力和自我反思、糾正機制,在數學、代碼、推理謎題等多種復雜任務上表現出色。模型用通專融合技術,基于大規...
-

MCP(Model Context Protocol,模型上下文協議)是一個開放協議,是Anthropic開源的,能實現大型語言模型(LLM)應用與外部數據源和工具之間的無縫集成。基于客戶端-服務器架構,支持多個服務連接到任...
-
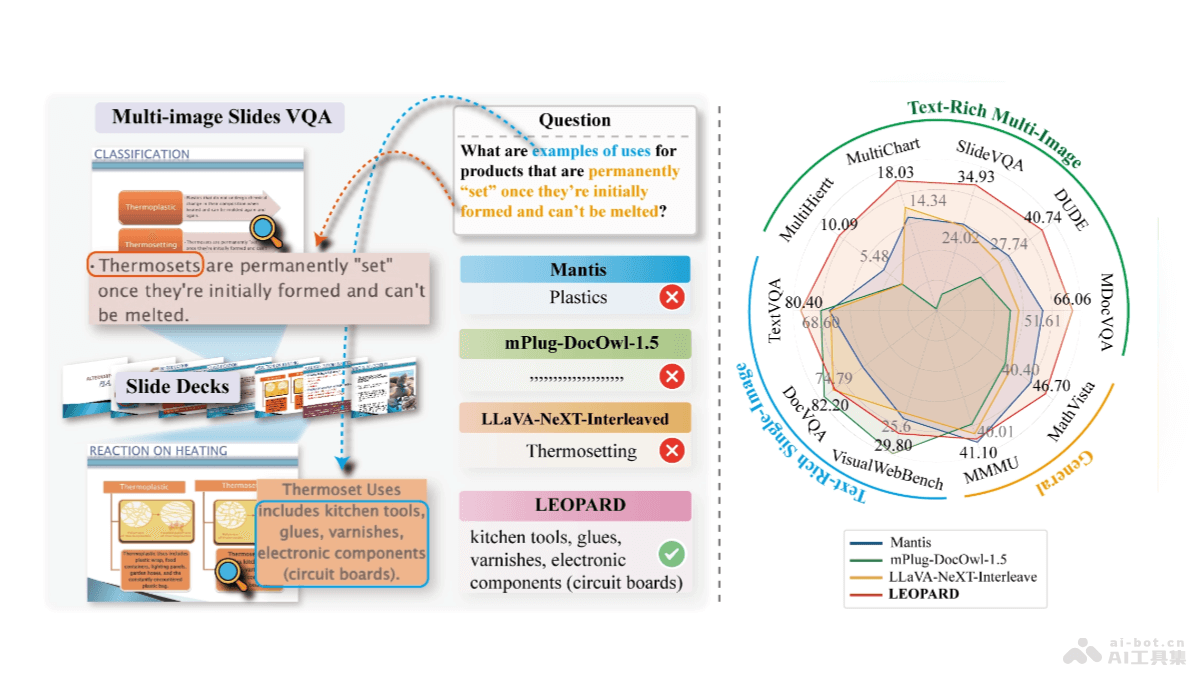
LEOPARD是騰訊AI Lab西雅圖實驗室推出的視覺語言模型,專為理解和處理含有大量文本的多圖像任務設計。LEOPARD基于兩個主要技術創新:一是策劃約一百萬條專門針對文本豐富、多圖像場景的高質量多模態指令調優數據集;二是...
-

LazyGraphRAG是微軟研究院推出的圖形增強生成增強檢索(RAG)框架,是GraphRAG的迭代版本。LazyGraphRAG在數據索引成本上大幅降低,是GraphRAG的0.1%,同時用新的混合數據搜索方法,提高生成...
-

Kandinsky-3是基于潛在擴散模型的文本到圖像(T2I)生成框架,以高質量和逼真度在圖像合成領域脫穎而出。Kandinsky-3能適應多種圖像生成任務,包括文本引導的修復/擴展、圖像融合、文本-圖像融合及視頻生成等。研...
-

CAVIA是蘋果公司、得克薩斯大學奧斯汀分校、谷歌聯合推出的多視角視頻生成框架,能將單一輸入圖像轉換成多個時空一致的視頻序列。框架基于引入視角集成注意力模塊,增強視頻的視角一致性和時間連貫性,支持用戶精確控制相機運動,同時保...
-

Flex3D是由Meta的GenAI團隊和牛津大學研究團隊推出的創新的兩階段3D生成框架,能基于任意數量的高質量輸入視圖,解決從文本、單張圖片或稀疏視圖圖像生成高質量3D內容的挑戰。第一階段,基于微調的多視圖和視頻擴散模型生...
-

EvolveDirector是阿里巴巴和南洋理工大學聯合推出的創新框架,用公開資源和高級模型的API接口訓練一個高性能的文本到圖像生成模型。框架基于與現有高級模型的API交互獲取數據對,訓練一個基礎模型,并借助預訓練的大型視...
